


Sharing our journey of learning world models from 790 years of long videos.
Over the past decade, AI progress has consistently come from compressing large-scale data into model parameters:
• AlexNet → 1.2M ImageNet images
• GPT-3 → 300B Common Crawl tokens
So what data modality remains massively underutilized yet fundamental?
Our answer: long videos.
Why long videos?
Because the world is not a set of isolated images or short captions. It is spatially and temporally extended multimodal experience.
Long videos capture rich context, causality, and temporal consistency. They are the closest public proxy to “the world unfolding.”
But they are also difficult to learn from: minute- or hour-long sequences, high redundancy, and multimodality.
The key question becomes: How can we turn raw long videos into something a model can learn efficiently, similar to how GPT learns from text?
Our insight: reduce long videos into frames and words. A simple three-step pipeline works surprisingly well:
1.ASR → convert audio into structured text with word-level timestamps
2.Keyframes → extract visually meaningful frames
3.Interleave frames and words → Frame → Text → Frame → Text …
The result is a multimodal sequence that represents the world as it unfolds.
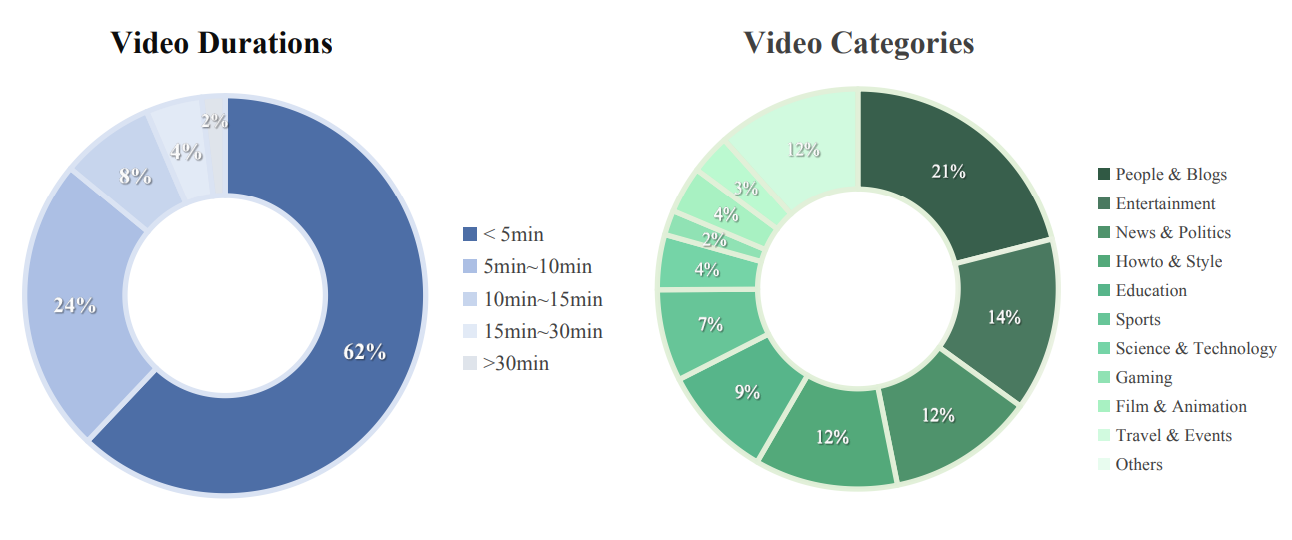
Data statistics of Emu3.5’s video interleaved data

Video interleaved data samples from Emu3.5’s pre-training dataset
Once long videos are converted into frames and words, we tokenize the sequence and train with a simple and scalable objective: next-token prediction (NTP).
No extra tasks.
No special losses.
No complex components.
Just as GPT learns the next word, a multimodal model can learn the next state.This simplicity is what makes scaling possible.
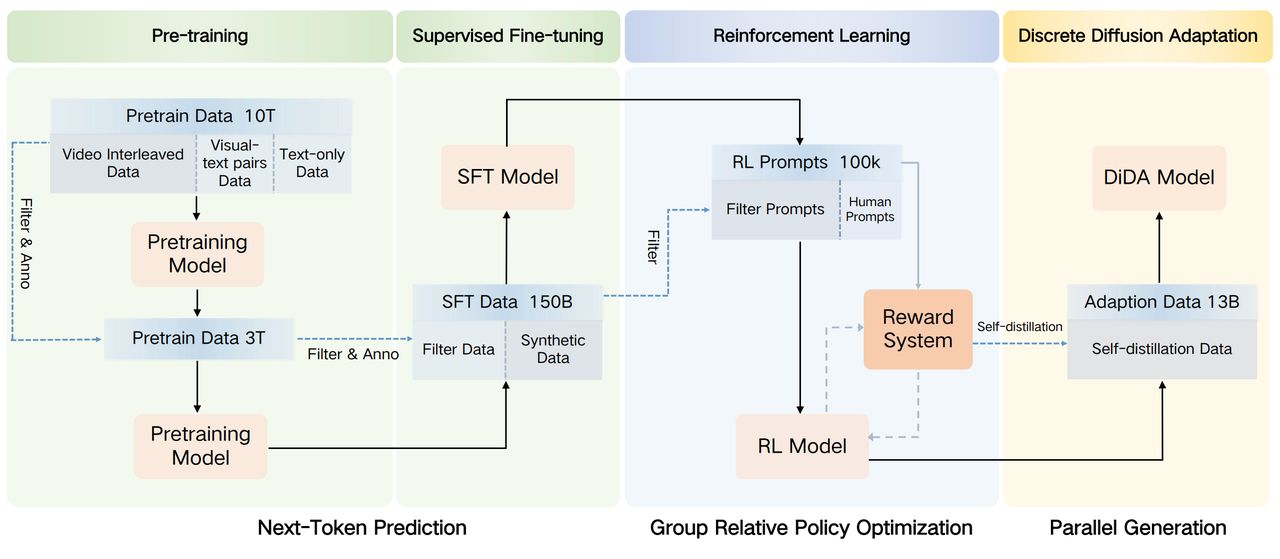
Overall training pipeline of Emu3.5
What emerges from long-video training?
Models begin to exhibit:
•long-range spatiotemporal consistency
•coherent visual–language generation
•open world any-to-image generation
•world exploration and manipulation
Directly from next-state prediction over long-horizon experience.

Prompt:Move the virtual camera down to show a street-level view

Prompt:Predict the next stage of the flower.

Prompt:The animal stands up, hiding behind a large red door and peeking its head out; predict what happens next.

Prompt:This is an urban village in Guangzhou. What will it look like in 10 years? And in 50 years?
Long videos are still vastly underexplored.
But they may be the richest, most scalable source of world knowledge available today.
As we scale data, modeling, and tokenization, we believe long videos will become a central fuel for world models, just as web text was for language models.